Analyzing the text-based content posted on social media in Pega 7.2.2
Complete this tutorial to use the Pega 7 Platform text mining capabilities to analyze the text data that is posted on Facebook, Twitter, and YouTube social media platforms. These platforms contain various types of unstructured data in the form of status messages, posts, comments, and so on. By analyzing this data, you can structure it and derive usable business information to deliver better services to customers and increase your customer base. For example, by tracking and analyzing tweets about your organization or your products, you can discover whether the customer response to the release of one of your products was positive or negative. This type of knowledge can help you quickly detect, respond to, and address your customers' needs and issues and, in consequence, retain and grow your customer base.
The Pega 7 Platform provides a collection of techniques that you can use to process and structure text data from social media platforms:
- Sentiment analysis – Detect and analyze the feelings (attitudes, emotions, opinions) that characterize a unit of text, for example, to find out whether a product review was positive or negative. Knowledge about customers' sentiments can be very important because customers often share their opinions, reactions, and attitudes toward products and services in social media. Additionally, customers are often influenced by opinions of others that they find online when they make buying decisions.
- Classification analysis – Assign one or more classes or categories to a text sample to make it easier to manage and sort. Classification analysis can help businesses improve the effectiveness of their customer support services. By classifying customer queries into various categories, the relevant information can be accessed more quickly, which increases the speed of customer support response times.
- Entity extraction analysis – Extract named entities from text data and assign the detected entities to predefined categories such as names of organizations, locations, people, quantities, or values. This type of analysis can help you track the activity of your customers and competitors or discover the products or features that customers comment on most often. You can combine entity extraction with sentiment analysis to detect whether the opinions about particular products or services are negative or positive.
Perform the following tasks to configure text analytics in your application:
- Creating a Data Set rule for social media.
- Creating a Text Analyzer rule.
- Creating a Data Flow rule for processing text data.
Creating a Data Set rule for social media
One of the most important tasks in establishing the infrastructure for text analytics is connecting your application with Facebook, Twitter, or YouTube API through Data Set rules. Each social media platform that you can mine for text data has a corresponding data set type in your application. Before you can connect your application with Facebook, Twitter or YouTube, you must register your application to obtain authentication credentials.
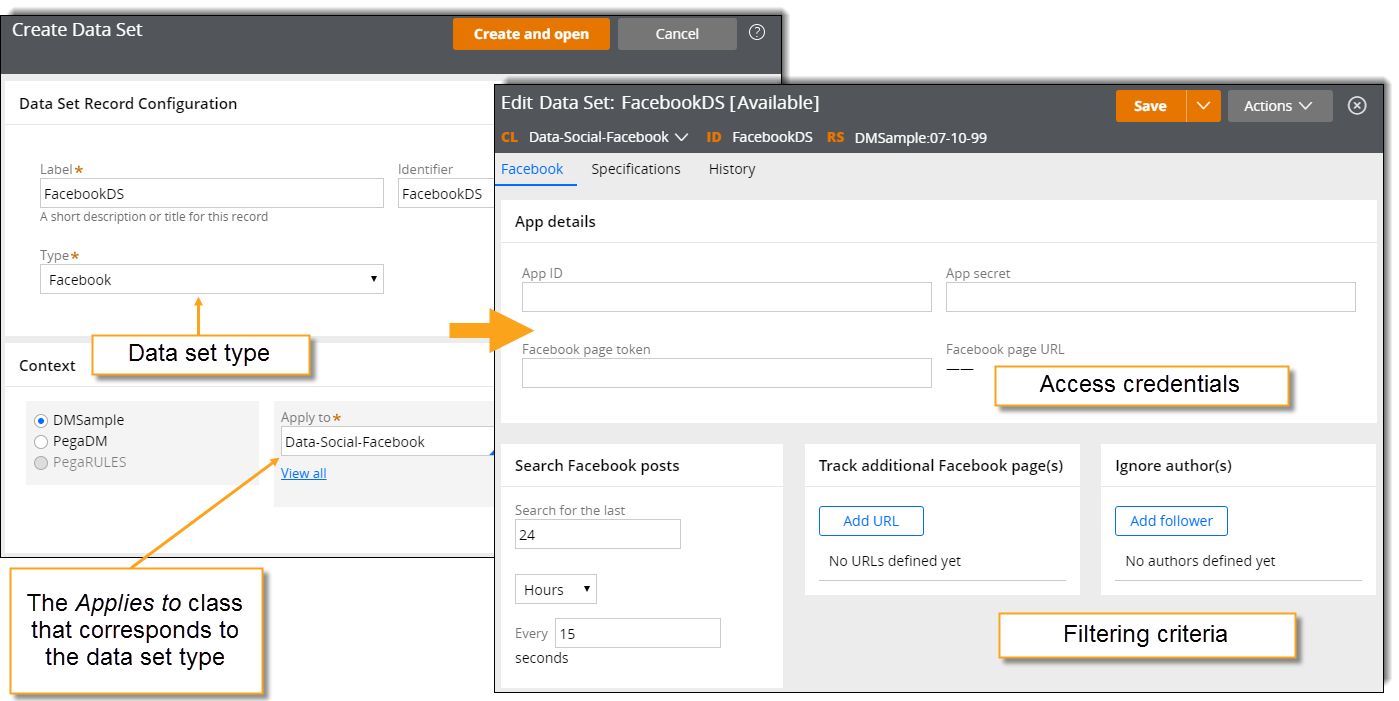
Sample data set for text mining
Creating a Text Analyzer rule
Use Text Analyzer rules to process the text data that your application sources from a Facebook, Twitter, or YouTube data set. You can use a variety of tools for analyzing and structuring the text data to obtain the business intelligence that is vital to accomplishing your business goals, such as identifying and responding to dissatisfied customers, discovering business trends, and so on.
- In the Records Explorer, expand the Decision list.
- Right-click Text Analyzer and click + Create.
- On the Create form, provide the following information for the new rule:
- Enter the rule label.
- Specify the ruleset, Applies To class, and ruleset version.
- Click Create and open.
- On the Select analysis tab of the Text Analyzer form, configure one or more of the following options:
- Configure sentiment analysis – Define the sentiment lexicons and models to use for opinion mining.
- Configure classification analysis – Define the taxonomy (that is, a collection of predefined categories that are associated with specific keywords) to use for detecting the categories that text data can be assigned to.
- Configure entity extraction analysis – Define topics, entity extraction models, and entity extraction rules to extract only the data that pertains to your subjects of interest.
Use the Text Analytics landing page to create and train custom models for sentiment and classification analysis. Through a four-step wizard, you define the type of the model and the training algorithm, upload training and testing data, train the model, and review its accuracy. You can use the models (as decision data binary files) in text analysis. You can also export the models. - On the I/O mapping tab of the Text Analyzer form, configure the following parameters:
- Input text: .pyText
- Outcome: .NLPOutcome
- On the Advanced tab of the Text Analyzer form, configure the following settings:
- Configure the language settings – Control how your application detects the language of the text data. For example, you can specify that the language is detected by your application or by the provider of the text data (for Twitter only).
- Configure the sentiment settings – Adjust the score range for sentiment detection. For example, by narrowing down the score range of the negative sentiment, you can identify only the most negative feedback that needs to be responded to quickly.
- Configure spelling checker – Enable the spelling checker to increase the confidence score of the data that you categorize (that is, the data is categorized more accurately).
- Configure classification settings – Define the granularity level for text classification (sentence level or document level). For example, select the sentence granularity level to classify smaller units of text such as comments or tweets.
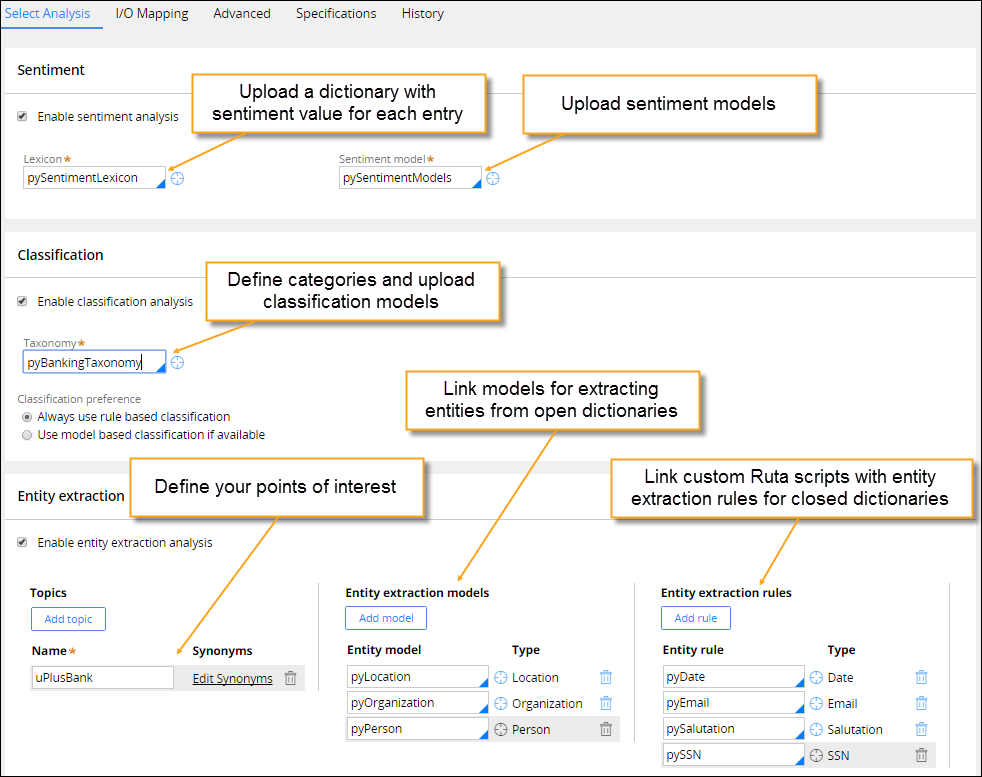
Select analysis tab on the Text Analyzer form
Creating a Data Flow rule for processing text data
After you create and configure a social media data set that tracks the relevant data, and you configure a Text Analyzer rule to process and structure that data, you must create a Data Flow rule. Minimally, this data flow must reference a social media data set as the source, a text analyzer to process the extracted text data, and a destination. The destination of the data flow can be an activity that writes the data flow results to a database.
- In the Records Explorer, expand the Data Model list.
- Right-click Data Flow and click + Create.
- On the Create form, provide the following information for the new rule:
- Enter the rule label.
- Specify the ruleset, Applies To class, and ruleset version.
The Applies To class of the Data Set and Data Flow rules must be the same.
- Click Create and open.
- Double-click the Source shape and perform the following actions:
- In the Source properties dialog box, from the list, select
- From the list, select a social media data set and click Submit.
- Click the connector that radiates from the Source shape and select Text Analyzer from the list.
- Double-click the Text Analyzer shape and perform the following actions:
- In the Text Analyzer properties dialog box, in the field, select your Text Analyzer rule.
- Click Submit.
- Double-click the Destination shape and perform the following actions:
- From the Destination list, select a destination type, for example, Activity.
- From the list that corresponds to the selected destination type, select a destination. For example, if you select Activity as the destination type, you can select the pxSaveSummaryForReporting activity to write the results to a database.
- Click Submit.
You can enrich your data flow with additional shapes, depending on your business objective. For example, if you analyze Twitter data, you can add a Filter shape between the Source and Text Analyzer shapes with .pyKloutScore >= 70 condition, to analyze only tweets from the most influential members of the audience. - Save the rule.
- In the Data Flows landing page, start a data flow run that references the Data Flow rule that you created to process the text data.
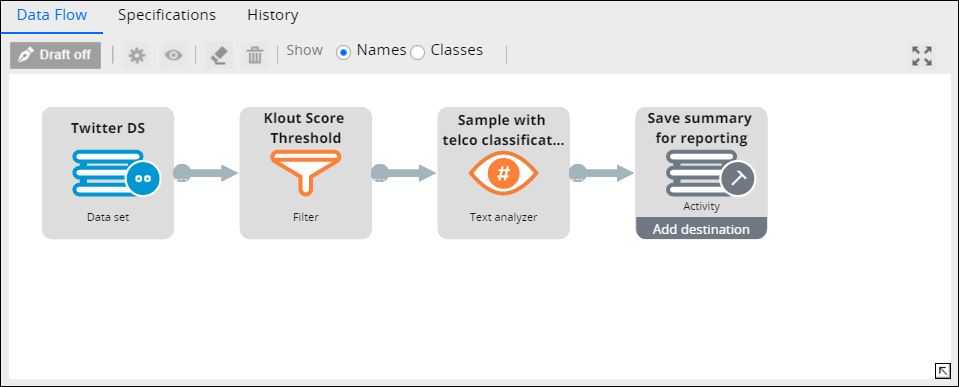
A data flow that processes text data from Twitter
For more information, see About Data Flow rules and Data Flows landing page.
In this tutorial, you created a data set to collect text data from social media platforms such as Facebook, Twitter, or YouTube and configured that data set to fetch only the data that is relevant to your business objectives. You created a Text Analyzer rule and customized the analytics processes to apply to the collected text data. Finally, you grouped all the rules that are relevant for your text analytics process in a data flow and arranged them in a processing pattern.
Previous topic Analyzing content from Webhose.io in NLP Sample in real time Next topic Intent analysis and filtering