Creating a Kinesis data set
You can create an instance of a Kinesis data set in Pega Platform to connect to an instance of Amazon Kinesis Data Streams. The Amazon Kinesis Data Streams service ingests a large amount of data in real time, durably stores it, and makes it available for lightweight processing.
For Pega Cloud applications, you can use a Pega-provided Kinesis data stream or connect to your own Kinesis data stream.
- In the header of Dev Studio, click .
- On the Create Data Set tab, in the Data Set Record
Configuration section, define the following settings to identify your data
set:
- In the Label field, enter the data set label.
- Optional: To change the automatically created identifier, click Edit, enter an identifier name, and then click OK.
- In the Type list, select Kinesis.
- In the Context section, specify the application context, applicable class, ruleset, and ruleset version of the data set.
- Click Create and open.
- In the Connection section, configure the connection to your AWS
Kinesis instance:
- In the Kinesis configuration instance, select the AWS authentication profile.
- In the Region field, select an AWS region.For more information about the available regions, see the AWS documentation.
Kinesis data set connection settings 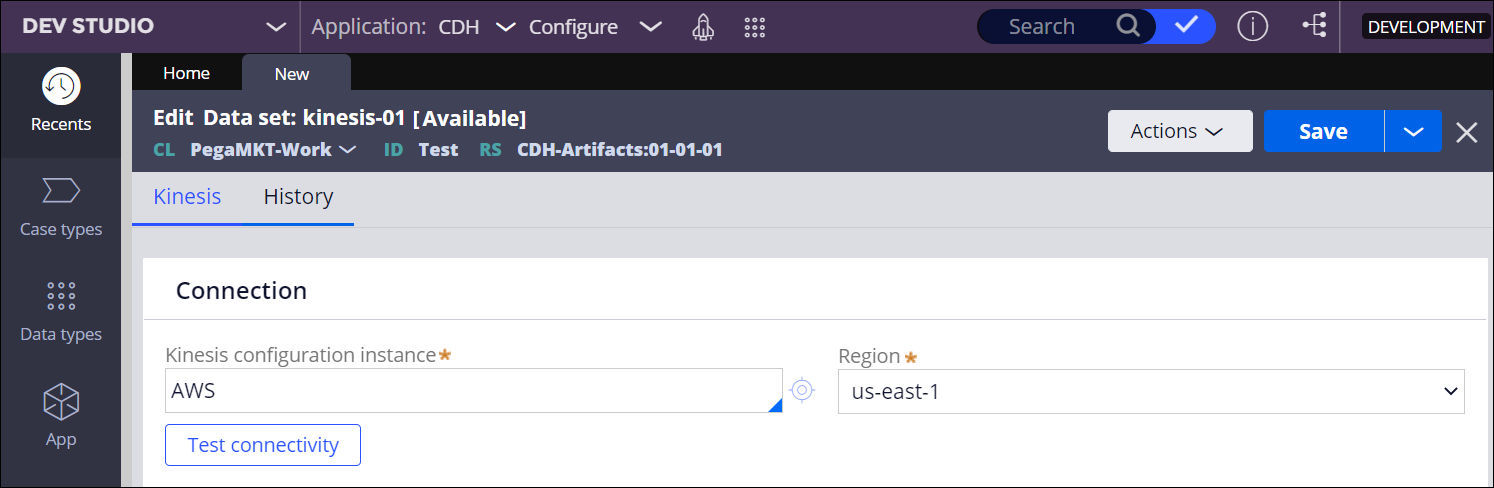
- In the Stream section, select a stream that is available in your
Kinesis configuration instance.
- Optional: In the Partition key(s) section, define the data set
partitioning.By configuring partitioning, you ensure that related records are sent to the same partition. If you do not define partition keys, the Kinesis data set randomly assigns records to partitions, which can hinder its performance.
- Click Add key.
- In the Key field, press the Down Arrow key to select the
property that you want the Kinesis data set to use as a partitioning key.
- Click Save.
Previous topic Creating a Kafka configuration instance Next topic Data transfer