Cassandra overview
Apache Cassandra is the primary means of storage for all of the customer, historical, and analytical data that you use in decision management. The following sections provide an overview of the most important Cassandra features in terms of scalability, data distribution, consistency, and architecture.
Apache Cassandra
- Distributed and decentralized
- Cassandra is a distributed system, which means that it is capable of running on multiple machines while appearing to users as a unified whole. Every node in a Cassandra cluster is identical. No single node performs organizational operations that are distinct from any other node. Instead, Cassandra features a peer-to-peer protocol and uses gossip to synchronize and maintain a list of nodes that are alive or dead.
- Elastically scalable
- The responsibility for data storage and processing is shared across many machine environments, to reduce the reliance on any one environment. Instead of hosting all data on a single server or replicating all of the data on all servers in a cluster, Cassandra divides portions of the data horizontally and hosts it separately.
- Consistent
-
In Cassandra, a read operation returns the most recently written value. For fault tolerance reasons, data is typically replicated across the cluster. You can control the number of replicas to block for all updates, by setting the consistency level against the replication factor.
The replication factor is the number of nodes in the cluster to which you want to propagate updates through add, update, or delete operations, and determines how much performance you give up, in order to gain more consistency.
The consistency level controls how many replicas in the cluster must acknowledge a write operation, or respond to a read operation, in order to be successful.
For example, you can set the consistency level to a number equal to the replication factor to gain stronger consistency at the cost of synchronous blocking operations, which wait for all nodes to be updated in order to declare success.
- Row and column-oriented
-
In Cassandra, rows do not need to have the same number of columns. Instead, column families arrange columns into tables and are controlled by keyspaces. A keyspace is a logical namespace that holds the column families, as well as certain configuration properties.
Decision Data Store
The Decision Data Store (DDS) is the repository for analytical data from a variety of sources. The DDS deploys as part of the Pega Platform node cluster and is supported by a Cassandra database. Each node that comprises the Decision Data Store handles data in JSON format for each customer, from different sources. The data is distributed and replicated around the cluster, and is stored in the node file system.
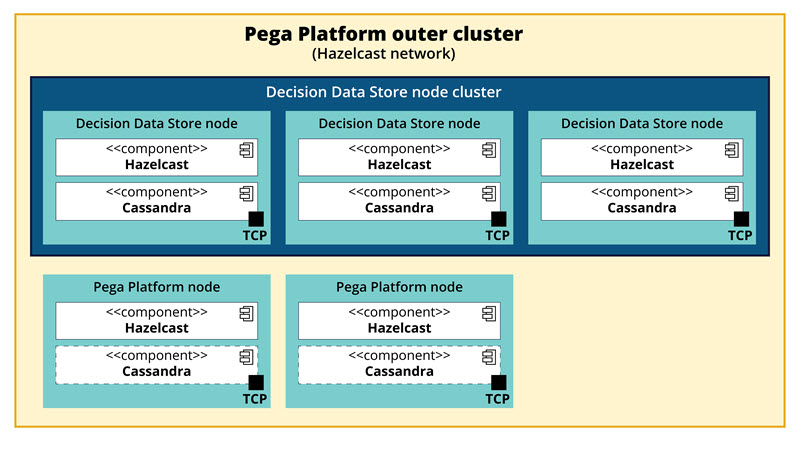
The following figure presents an example Decision Data Store node cluster. Each DDS node contains a Cassandra database process. The nodes outside of the DDS node cluster are Pega Platform nodes that you can include in the DDS cluster, by deploying the Cassandra database. Pega Platform nodes communicate with the DDS nodes for reading and writing operations.
Figure: Apache Cassandra in Pega Platform
Deployment options
- Managed
-
In this model, the nodes (machine environments) that are designated to hosting the Decision Data Store have their Cassandra Java Virtual machine (JVM) started and stopped for them, by the JVM that is hosting the Pega Platform instance. For more information, see Configuring an internal Cassandra database.
- External
-
Use this option when you are already using Cassandra within your IT infrastructure, and want the solutions you build with Pega Platform to conform to this architecture and operational management. For more information, see Connecting to an external Cassandra database.
For more information, see the Apache Cassandra documentation.