Creating an ingestion case
This content applies only to Pega Cloud environments
Configure the ingestion data flows as Pega cases. By using the case process, you can also schedule certain ingestion runs to off hours to avoid executing batch processes during peak daytime processing.
The following figure provides an overview of an ingestion case that can be used to ingest and process customer data.
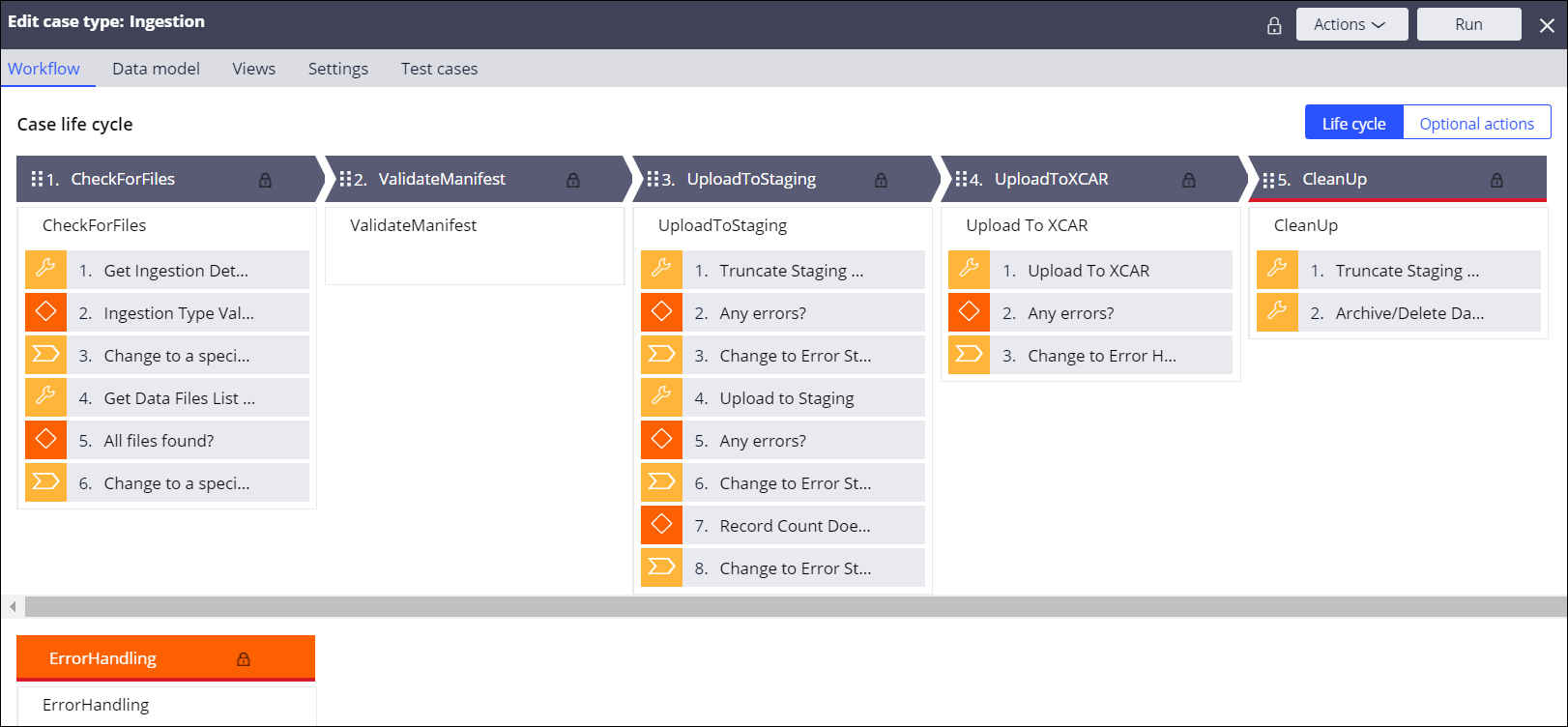
For more information about creating case types, see Automating work by creating case types.
Checking for files
This stage validates that all data files identified in the manifest file for a given ingestion execution are present in the data folder.
You can use repository APIs for all file-related operations. For more information, see Repository APIs.
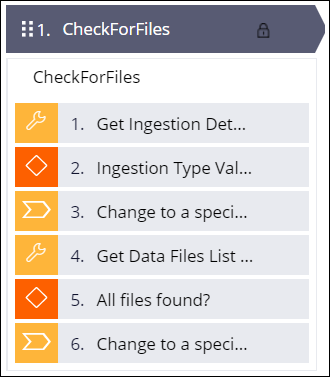
- Get ingestion details.
- Validate the ingestion process.
Options Actions SFTP process guarantees that the manifest file is delivered after the data files were transferred - Add a decision step to compare the number of records processed in the data flow to the number of records identified in the manifest file.
- If the numbers match, go to the next stage.
- If the numbers do not match, go to the error stage.
SFTP process cannot guarantee that the manifest file is delivered after the data files were transferred and token files are used - Configure the case to wait until all the token files arrive in the destination by routing the case to a work basket and use an SLA agent to check for the files at specified intervals.
- If all token files are present, go to the next stage.
- If not all token files are present (not all data files were transferred), go to the error stage.
- Perform other validations if required, for example, size validation:
- If validation passes, go to the next stage.
- If validation fails, go to the error stage.
By default, data files are sent in compressed mode which supports the.zipand.gzipcompression formats. If data files are compressed, size validation is not possible. If you perform size validation, you cannot use the out-of-the-box support for reading compressed files.
Uploading to the staging data set
Add this stage if your application requires data validation. Otherwise, this stage is optional. As a best practice, ensure that all the data was successfully read from all the data files before you upload the data to a permanent data set.

- Truncate the staging data set.
- Add a decision step to check for errors that might have occurred during the
truncate operation.
- If there are no errors, go to the next stage.
- If errors occur, go to the error stage.
- Add a step to execute the data flow to read data from the individual files that
were transferred and load them into one temporary/staging location.For more information, see Triggering the customer data ingestion process.
Using a Cassandra data set improves processing by taking advantage of the inherent Cassandra high-speed processing capabilities.
- Add a decision step to check for errors that might have occurred during the
upload.
- If there are no errors, go to the next stage.
- If errors occur, go to the error stage.
- Add a decision step to compare the number of records processed in the data flow
to the number of records identified in the manifest file.
- If the numbers match, go to the next stage.
- If the numbers do not match, go to the error stage.
For critical customer data, exact match is required. However, for non-critical data, you can identify a tolerance to allow processing to continue if there is no match.
If optional size validation and non-standard decryption are required, these operations are performed at this point. Processing size validation might not be applicable if you are transferring compressed files. Both size validation and decryption require project development work, which in some cases might require Java development skills depending on the decompression and decryption algorithms used.
- Add data flow run details to the case review screen to help debugging issues.
Uploading to the final data set
Typically, there are multiple data flows that process the data to a destination depending on the data (customer, product, transactions, and so on) and action to be performed.
You can upload the data to a relational database (PostgreSQL for Pega Cloud) or to xCAR in a Cassandra database. In both cases, the data can be processed in one execution run by identifying a single data flow in the manifest file which executes the appropriate data flows.
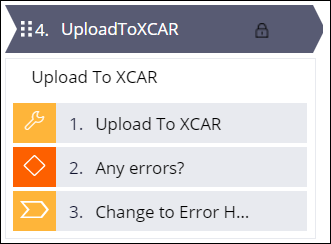
- Add a step to execute the data flow to read from the staging data set and load
the to the destination data set.For more information, see Triggering the customer data ingestion process.
The following operations are supported:
- Upsert
- Insert a record if one does not exist or update an existing record.
- Delete
- Delete a record from the specified destination.
- Add a decision step to check for errors.
- If there are no errors, go to the next stage.
- If errors occur, go to the error stage.
- Add data flow run details to the case review screen to help debugging issues.
Cleanup
In the cleanup stage, you archive (if needed) or delete the files that were transferred to the Pega Cloud File Storage.
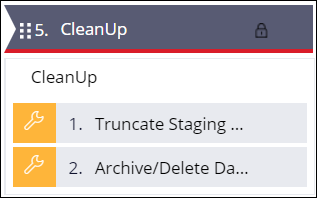
- Truncate the staging data set.This step is an extra check to ensure that the staging data set is empty before the next load begins. If Cassandra is used as the staging data set, Cassandra compaction occurs automatically, which might impact system performance.
- Archive or delete the files received in the Pega Cloud File Storage.
- At the end of a successful run, resolve the case.For more information, see Configuring a case resolution.
Handling errors
In the error stage, you archive (if needed) or delete the files that were transferred to the Pega Cloud File Storage up to the point when an error in the ingestion process occurred.
- Send an error notification to the appropriate client support team with details of the error.
- Archive or delete the files received in the Pega Cloud File Storage.
- Truncate the staging data set.This step is an extra check to ensure that the staging data set is empty before the next load begins. If Cassandra is used as the staging data set, Cassandra compaction occurs automatically, which might impact system performance.
Previous topic Triggering the customer data ingestion process Next topic Exporting customer data from Pega Customer Decision Hub