Best practices for pattern extraction in text analytics
Apache Ruta (Rule-based Text Annotation) is a rule-based language that you can use to detect keywords and phrases that follow certain patterns to populate a case, route an assignment, and so on. Example patterns can include:
- Lists of possible words, such as product or country names
- Patterns that you can detect through regular expressions, for example, flight numbers, phone numbers, or email addresses
- Patterns that you can recognize across multiple tokens, for example, hotel or street names
Learn about rule-based text extraction in Pega Platformthrough the following topics:
Introduction to Ruta
The Ruta language classifies entities based on rules that are combinations of annotation patterns, optional quantifiers, conditions for matching, and actions to perform. Consider the following example:
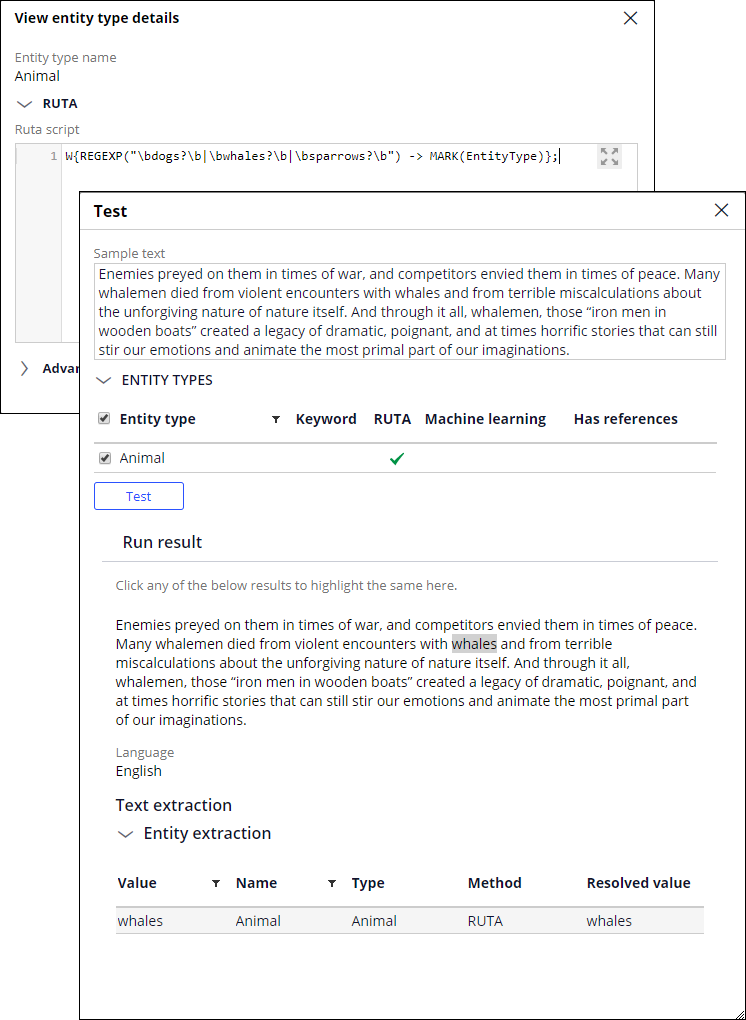
In this example:
Wis an annotation of typenormal wordREGEXP("\bdogs?\b|\bwhales?\b|\bsparrows?\b")is a condition that is fulfilled when a normal word matches the regular expression.->separates conditions from actions.MARK(EntityType)is the action that is taken when a piece of text fulfills the condition. In this case, the entity model marks an entity of typeAnimal.
For more information about the Ruta language, including a full list of annotation types, quantifiers, and examples, see the Apache Documentation.
Ruta requirements and considerations for Pega applications
Consider the following points when creating Ruta-based entity types in Pega Platform:
- To store annotation results, mark them in the Ruta script. You can use the
VarA,VarB,VarC,VarD, andVarEvariables to store intermediate annotation results. Pega Platform stores the final annotation results in theEntityTypeannotation, the name of which is equal to the Entity type name property - Always clear the declared variables, such as
VarA, at the end of your script, so that they do not interfere with the execution of the next script. - Pega Platform does not support
WORDLISTandWORDTABLEannotations. Starting from Pega Platform 8.3, you can define wordlists as keywords and refer to them in the Ruta script. - Starting from Pega Platform 8.3, you can reference other
entity types through the Ruta script by using the following command:
EntityType{FEATURE("entityType", "<EntityTypeNameInLowerCase>")}. For an example of a use case, see Improve the management of text extraction models through entity types.Reference entity types in lowercase, irrespective of the case in which you defined them. - In Pega Platform, Ruta script can detect only a single entity type.
For more information, see Creating entity models.
Examples of Ruta scripts
To create custom Ruta-based entity types, you can use any of the provided default templates. The following list also provides a number of simple but efficient Ruta scripts that you can use to recognize basic entity types in your application.
- To detect only words, for example, telephone,
enter:
W {-> MARK(EntityType)}; - To detect letters or words that are followed by numbers, for example,
SK123,
enter:
W NUM {-> MARK(EntityType,1,2)}; - To detect numbers that are surrounded by letters of words, for example,
IFSC000ABC, enter:
Digits 1 and 3 specify the number of annotations to mark as
W NUM W {-> MARK(EntityType,1,3)};EntityType(from annotation 1 to annotation 3). - To detect a string of specific length, for example, six digits, enter:
or
NUM{REGEXP(“……”) -> MARK(EntityType)};NUM{REGEXP(“.{6}”) -> MARK(EntityType)}; - To detect case-insensitive strings, for example, USA or India, enter:
In the example above,
W{REGEXP(“(?i)(usa | india)”) -> MARK(EntityType)};(?i)indicates that the script ignores the case. - To detect a specific word or phrase that is followed by a space and then a
number, for example, INTL 1001, enter:
Document{-> RETAINTYPE(SPACE)};In the example above, the Ruta script does not detect INTL1001 because the string does not contain a space. By default, Ruta ignores spaces, unless you specify otherwise (for example, through theW{ REGEXP(“INTL”)} SPACE NUM {-> MARK(EntityType,1,3)}RETAINTYPE(SPACE)command). - To detect alphanumeric patterns through token annotation, for example, A1B23C,
enter:
To fulfill all conditions within the token annotation, use the AND condition.
Token{ AND(CONTAINS(NUM),CONTAINS(W)) -> MARK(EntityType)}; - To detect patterns through a regular expression, for example, two-digit
hexadecimal numbers, enter:
((W|NUM) (NUM|W)*){REGEXP("[a-fA-F0-9]{2}") -> MARK(EntityType)}; - To declare a temporary variable, for example,
VarAthat represents the name of the month, enter:DECLARE VarA; //Month name - To clear a declared variable, for example,
VarA, enter:VarA{->UNMARK(VarA)}
For an example use case, seeDetecting transaction details with Ruta
Previous topic Creating entity models Next topic Detecting transaction details with Ruta